|
|
Biofelsefe — Moleküler Bioloji
|
|
|
|
| |
|
| |
Molecular biology
Molecular biology (W)
Molecular biology is the branch of biology that concerns the molecular basis of biological activity in and between cells, including molecular synthesis, modification, mechanisms and interactions. The central dogma of molecular biology describes the process in which DNA is transcribed into RNA then translated into protein.
William Astbury described molecular biology in 1961 in Nature, as:
“...not so much a technique as an approach, an approach from the viewpoint of the so-called basic sciences with the leading idea of searching below the large-scale manifestations of classical biology for the corresponding molecular plan. It is concerned particularly with the forms of biological molecules and [...] is predominantly three-dimensional and structural – which does not mean, however, that it is merely a refinement of morphology. It must at the same time inquire into genesis and function.”
Some clinical research and medical therapies arising from molecular biology are covered under gene therapy whereas the use of molecular biology or molecular cell biology in medicine is now referred to as molecular medicine. Molecular biology also plays important role in understanding formations, actions, and regulations of various parts of cells which can be used to efficiently target new drugs, diagnose disease, and understand the physiology of the cell. |
|
| |
| |
History
|
History
History (W)
While molecular biology was established as an official branch of science in the 1930s, the term wasn't coined until 1938 by Warren Weaver. At the time, Weaver was the director of Natural Sciences for the Rockefeller Foundation and believed that biology was about to undergo significant change due to recent advancements in technology such as X-ray crystallography.
Molecular biology arose as an attempt to answer the questions regarding the mechanisms of genetic inheritance and the structure of a gene. In 1953, James Watson and Francis Crick published the double helical structure of DNA courtesy of the X-ray crystallography work done by Rosalind Franklin and Maurice Wilkins. Watson and Crick described the structure of DNA and the interactions within the molecule. This publication jump-started research into molecular biology and increased interest in the subject. |
|
|
|
| |
Relationship to other biological sciences
|
Relationship to other biological sciences
Relationship to other biological sciences (W)
The following list describes a viewpoint on the interdisciplinary relationships between molecular biology and other related fields.
While researchers practice techniques specific to molecular biology, it is common to combine these with methods from genetics and biochemistry. Much of molecular biology is quantitative, and recently a significant amount of work has been done using computer science techniques such as bioinformatics and computational biology.
Molecular genetics, the study of gene structure and function, has been among the most prominent sub-fields of molecular biology since the early 2000s. Other branches of biology are informed by molecular biology, by either directly studying the interactions of molecules in their own right such as in cell biology and developmental biology, or indirectly, where molecular techniques are used to infer historical attributes of populations or species, as in fields in evolutionary biology such as population genetics and phylogenetics. There is also a long tradition of studying biomolecules "from the ground up", or molecularly, in biophysics. |

|
|
|
|
| |
Techniques of molecular biology
|
Techniques of molecular biology
|
|
|
Molecular cloning
Molecular cloning (W)
One of the most basic techniques of molecular biology to study protein function is molecular cloning. In this technique, DNA coding for a protein of interest is cloned using polymerase chain reaction (PCR), and/or restriction enzymes into a plasmid (expression vector). A vector has 3 distinctive features: an origin of replication, a multiple cloning site (MCS), and a selective marker usually antibiotic resistance. Located upstream of the multiple cloning site are the promoter regions and the transcription start site which regulate the expression of cloned gene. This plasmid can be inserted into either bacterial or animal cells. Introducing DNA into bacterial cells can be done by transformation via uptake of naked DNA, conjugation via cell-cell contact or by transduction via viral vector. Introducing DNA into eukaryotic cells, such as animal cells, by physical or chemical means is called transfection. Several different transfection techniques are available, such as calcium phosphate transfection, electroporation, microinjection and liposome transfection. The plasmid may be integrated into the genome, resulting in a stable transfection, or may remain independent of the genome, called transient transfection.
DNA coding for a protein of interest is now inside a cell, and the protein can now be expressed. A variety of systems, such as inducible promoters and specific cell-signaling factors, are available to help express the protein of interest at high levels. Large quantities of a protein can then be extracted from the bacterial or eukaryotic cell. The protein can be tested for enzymatic activity under a variety of situations, the protein may be crystallized so its tertiary structure can be studied, or, in the pharmaceutical industry, the activity of new drugs against the protein can be studied.
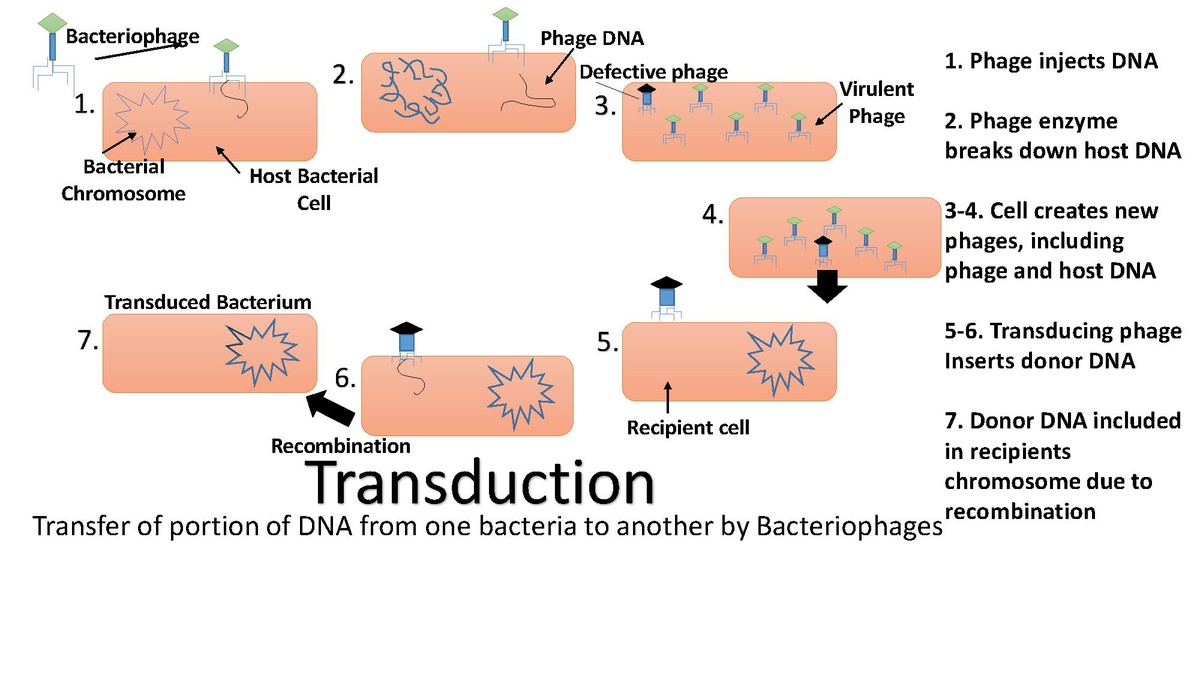
Transduction image. |
|
|
| |
|
|
|
|
|
|
Polymerase chain reaction
Polymerase chain reaction (W)
Polymerase chain reaction (PCR) is an extremely versatile technique for copying DNA. In brief, PCR allows a specific DNA sequence to be copied or modified in predetermined ways. The reaction is extremely powerful and under perfect conditions could amplify one DNA molecule to become 1.07 billion molecules in less than two hours. The PCR technique can be used to introduce restriction enzyme sites to ends of DNA molecules, or to mutate particular bases of DNA, the latter is a method referred to as site-directed mutagenesis. PCR can also be used to determine whether a particular DNA fragment is found in a cDNA library. PCR has many variations, like reverse transcription PCR (RT-PCR) for amplification of RNA, and, more recently, quantitative PCR which allow for quantitative measurement of DNA or RNA molecules. |
|
|
|
Gel electrophoresis
Gel electrophoresis (W)
.jpg)
Two percent agarose gel in borate buffer cast in a gel tray. |
|
|
| |
|
Gel electrophoresis is one of the principal tools of molecular biology. The basic principle is that DNA, RNA, and proteins can all be separated by means of an electric field and size. In agarose gel electrophoresis, DNA and RNA can be separated on the basis of size by running the DNA through an electrically charged agarose gel. Proteins can be separated on the basis of size by using an SDS-PAGE gel, or on the basis of size and their electric charge by using what is known as a 2D gel electrophoresis. |
|
|
|
Macromolecule blotting and probing
Macromolecule blotting and probing (W)
The terms northern, western and eastern blotting are derived from what initially was a molecular biology joke that played on the term Southern blotting, after the technique described by Edwin Southern for the hybridisation of blotted DNA. Patricia Thomas, developer of the RNA blot which then became known as the northern blot, actually didn't use the term.
Southern blotting
Named after its inventor, biologist Edwin Southern, the Southern blot is a method for probing for the presence of a specific DNA sequence within a DNA sample. DNA samples before or after restriction enzyme (restriction endonuclease) digestion are separated by gel electrophoresis and then transferred to a membrane by blotting via capillary action. The membrane is then exposed to a labeled DNA probe that has a complement base sequence to the sequence on the DNA of interest. Southern blotting is less commonly used in laboratory science due to the capacity of other techniques, such as PCR, to detect specific DNA sequences from DNA samples. These blots are still used for some applications, however, such as measuring transgene copy number in transgenic mice or in the engineering of gene knockout embryonic stem cell lines.
Northern blotting
The northern blot is used to study the expression patterns of a specific type of RNA molecule as relative comparison among a set of different samples of RNA. It is essentially a combination of denaturing RNA gel electrophoresis, and a blot. In this process RNA is separated based on size and is then transferred to a membrane that is then probed with a labeled complement of a sequence of interest. The results may be visualized through a variety of ways depending on the label used; however, most result in the revelation of bands representing the sizes of the RNA detected in sample. The intensity of these bands is related to the amount of the target RNA in the samples analyzed. The procedure is commonly used to study when and how much gene expression is occurring by measuring how much of that RNA is present in different samples. It is one of the most basic tools for determining at what time, and under what conditions, certain genes are expressed in living tissues.
Western blotting
In western blotting, proteins are first separated by size, in a thin gel sandwiched between two glass plates in a technique known as SDS-PAGE. The proteins in the gel are then transferred to a polyvinylidene fluoride (PVDF), nitrocellulose, nylon, or other support membrane. This membrane can then be probed with solutions of antibodies. Antibodies that specifically bind to the protein of interest can then be visualized by a variety of techniques, including colored products, chemiluminescence, or autoradiography. Often, the antibodies are labeled with enzymes. When a chemiluminescent substrate is exposed to the enzyme it allows detection. Using western blotting techniques allows not only detection but also quantitative analysis. Analogous methods to western blotting can be used to directly stain specific proteins in live cells or tissue sections.
Eastern blotting[edit]
The eastern blotting technique is used to detect post-translational modification of proteins. Proteins blotted on to the PVDF or nitrocellulose membrane are probed for modifications using specific substrates. |
|
|
|
|
Microarrays
Microarrays (W)
A DNA microarray is a collection of spots attached to a solid support such as a microscope slide where each spot contains one or more single-stranded DNA oligonucleotide fragments. Arrays make it possible to put down large quantities of very small (100 micrometre diameter) spots on a single slide. Each spot has a DNA fragment molecule that is complementary to a single DNA sequence. A variation of this technique allows the gene expression of an organism at a particular stage in development to be qualified (expression profiling). In this technique the RNA in a tissue is isolated and converted to labeled complementary DNA (cDNA). This cDNA is then hybridized to the fragments on the array and visualization of the hybridization can be done. Since multiple arrays can be made with exactly the same position of fragments, they are particularly useful for comparing the gene expression of two different tissues, such as a healthy and cancerous tissue. Also, one can measure what genes are expressed and how that expression changes with time or with other factors. There are many different ways to fabricate microarrays; the most common are silicon chips, microscope slides with spots of ~100 micrometre diameter, custom arrays, and arrays with larger spots on porous membranes (macroarrays). There can be anywhere from 100 spots to more than 10,000 on a given array. Arrays can also be made with molecules other than DNA. |
| |
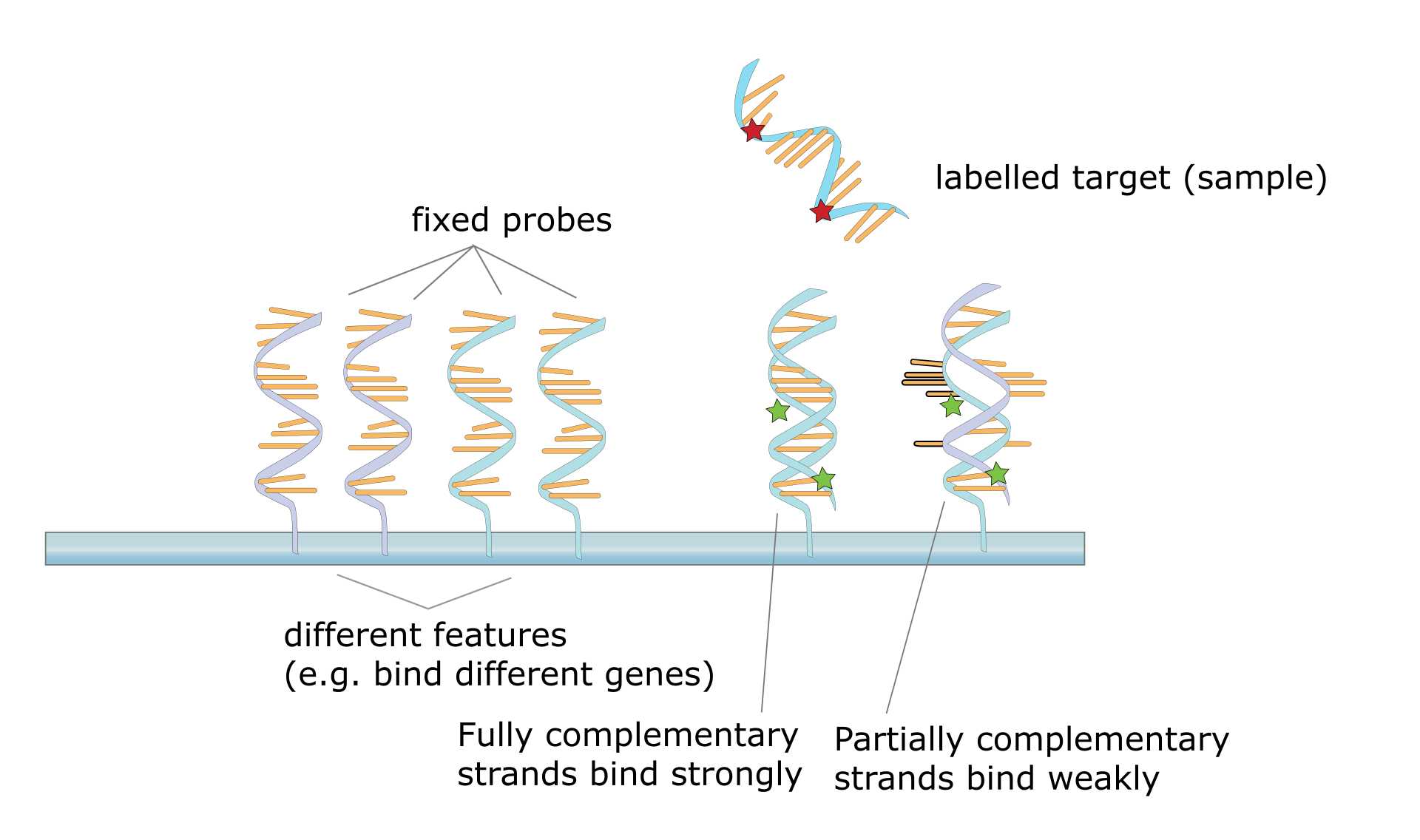
Hybridization of target to probe. |
|
|
|
|
|
|
Allele-specific oligonucleotide
Allele-specific oligonucleotide (W)
Allele-specific oligonucleotide (ASO) is a technique that allows detection of single base mutations without the need for PCR or gel electrophoresis. Short (20–25 nucleotides in length), labeled probes are exposed to the non-fragmented target DNA, hybridization occurs with high specificity due to the short length of the probes and even a single base change will hinder hybridization. The target DNA is then washed and the labeled probes that didn't hybridize are removed. The target DNA is then analyzed for the presence of the probe via radioactivity or fluorescence. In this experiment, as in most molecular biology techniques, a control must be used to ensure successful experimentation.
In molecular biology, procedures and technologies are continually being developed and older technologies abandoned. For example, before the advent of DNA gel electrophoresis (agarose or polyacrylamide), the size of DNA molecules was typically determined by rate sedimentation in sucrose gradients, a slow and labor-intensive technique requiring expensive instrumentation; prior to sucrose gradients, viscometry was used. Aside from their historical interest, it is often worth knowing about older technology, as it is occasionally useful to solve another new problem for which the newer technique is inappropriate. |
|
|
|
|
|
|
|
|
|
|
| |
| |
|
| |
| |
Central dogma of molecular biology (W) |
Central dogma of molecular biology
Central dogma of molecular biology (W)
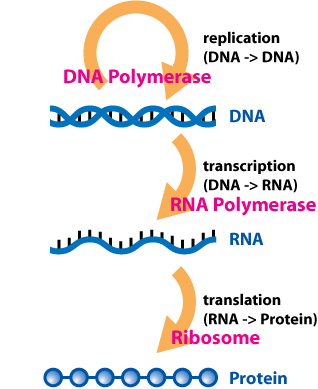
The central dogma of molecular biology is an explanation of the flow of genetic information within a biological system. it is often stated as “DNA makes RNA, and RNA makes protein,” although this is not its original meaning. It was first stated by Francis Crick in 1957, then published in 1958:
“The Central Dogma. This states that once "information" has passed into protein it cannot get out again. In more detail, the transfer of information from nucleic acid to nucleic acid, or from nucleic acid to protein may be possible, but transfer from protein to protein, or from protein to nucleic acid is impossible. Information means here the precise determination of sequence, either of bases in the nucleic acid or of amino acid residues in the protein.”
— Francis Crick, 1958
and re-stated in a Nature paper published in 1970:
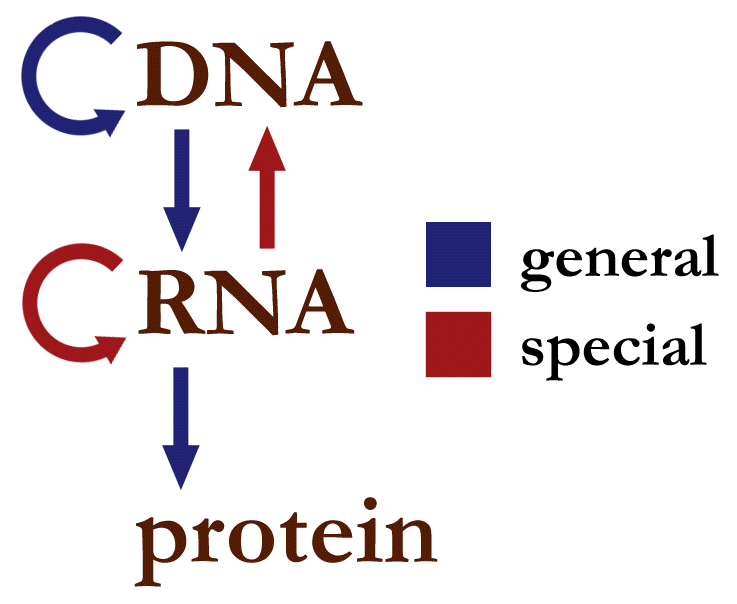
Information flow in biological systems. |
|
|
| |
|
“The central dogma of molecular biology deals with the detailed residue-by-residue transfer of sequential information. It states that such information cannot be transferred back from protein to either protein or nucleic acid.”
— Francis Crick
A second version of the central dogma is popular but incorrect. This is the simplistic DNA → RNA → protein pathway published by James Watson in the first edition of The Molecular Biology of the Gene (1965). Watson's version differs from Crick's because Watson describes a two-step (DNA → RNA and RNA → protein) process as the central dogma. While the dogma, as originally stated by Crick, remains valid today, Watson's version does not.
The dogma is a framework for understanding the transfer of sequence information between information-carrying biopolymers, in the most common or general case, in living organisms. There are 3 major classes of such biopolymers: DNA and RNA (both nucleic acids), and protein. There are 3 × 3 = 9 conceivable direct transfers of information that can occur between these. The dogma classes these into 3 groups of 3: three general transfers (believed to occur normally in most cells), three special transfers (known to occur, but only under specific conditions in case of some viruses or in a laboratory), and three unknown transfers (believed never to occur). The general transfers describe the normal flow of biological information: DNA can be copied to DNA (DNA replication), DNA information can be copied into mRNA (transcription), and proteins can be synthesized using the information in mRNA as a template (translation). The special transfers describe: RNA being copied from RNA (RNA replication), DNA being synthesised using an RNA template (reverse transcription), and proteins being synthesised directly from a DNA template without the use of mRNA. The unknown transfers describe: a protein being copied from a protein, synthesis of RNA using the primary structure of a protein as a template, and DNA synthesis using the primary structure of a protein as a template - these are not thought to naturally occur. |
|
| |
| |
Biological sequence information
|
Biological sequence information
Biological sequence information (W)
The biopolymers that comprise DNA, RNA and (poly)peptides are linear polymers (i.e.: each monomer is connected to at most two other monomers). The sequence of their monomers effectively encodes information. The transfers of information described by the central dogma ideally are faithful, deterministic transfers, wherein one biopolymer's sequence is used as a template for the construction of another biopolymer with a sequence that is entirely dependent on the original biopolymer's sequence. |
|
|
|
| |
General transfers of biological sequential information
|
General transfers of biological sequential information
General transfers of biological sequential information (W)
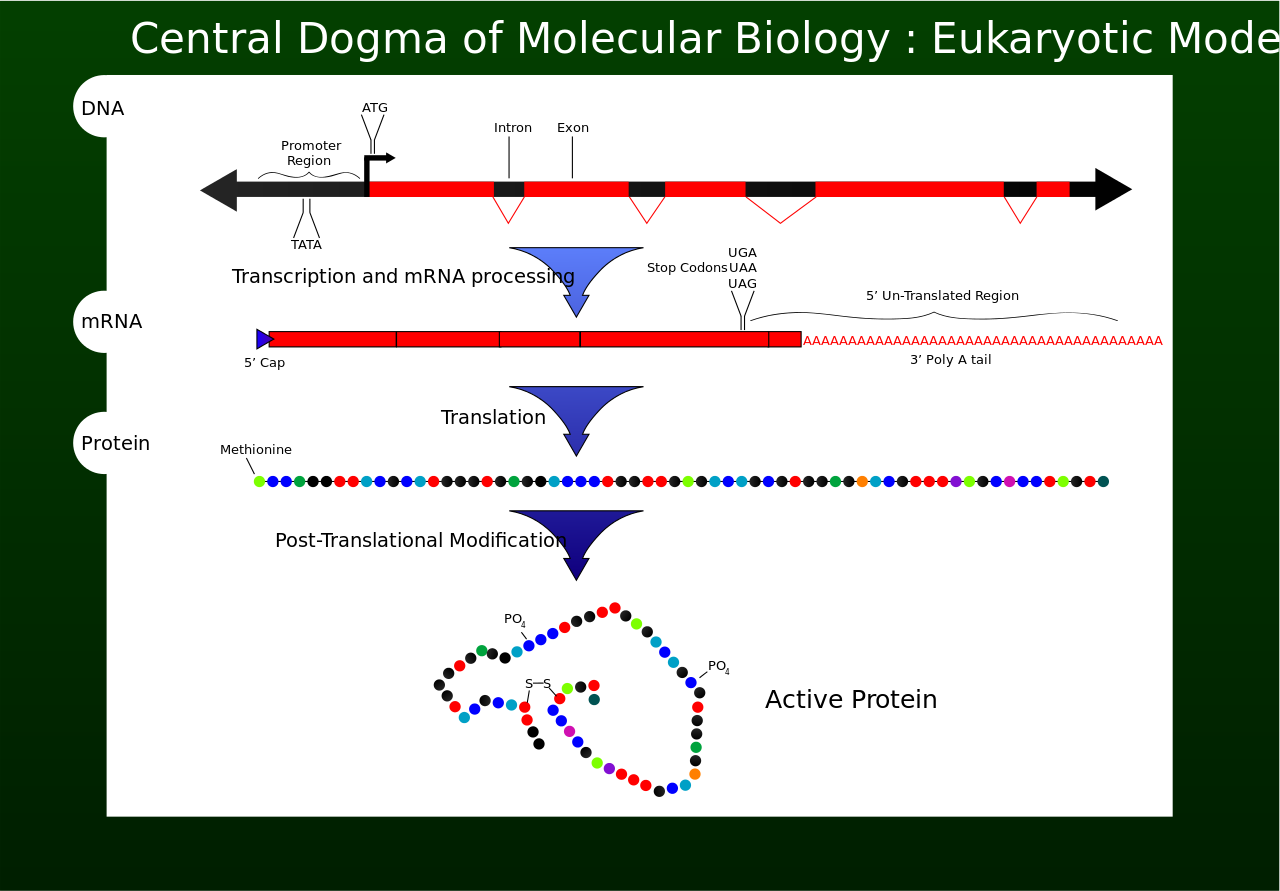
Overview of the central dogma of molecular biology. Original work by Mike Jones for wikipedia. |
|
|
| |
| Table of the three classes of information transfer suggested by the dogma |
| General |
Special |
Unknown |
| DNA → DNA |
RNA → DNA |
protein → DNA |
| DNA → RNA |
RNA → RNA |
protein → RNA |
| RNA → protein |
DNA → protein |
protein → protein |
|
|
|
|
DNA replications
DNA replications (W)
In the sense that DNA replication must occur if genetic material is to be provided for the progeny of any cell, whether somatic or reproductive, the copying from DNA to DNA arguably is the fundamental step in the central dogma. A complex group of proteins called the replisome performs the replication of the information from the parent strand to the complementary daughter strand.
The replisome comprises:
This process typically takes place during S phase of the cell cycle. |
|
|
|
|
Transcription
Transcription (W)
Transcription is the process by which the information contained in a section of DNA is replicated in the form of a newly assembled piece of messenger RNA (mRNA). Enzymes facilitating the process include RNA polymerase and transcription factors. In eukaryotic cells the primary transcript is pre-mRNA. Pre-mRNA must be processed for translation to proceed. Processing includes the addition of a 5' cap and a poly-A tail to the pre-mRNA chain, followed by splicing. Alternative splicing occurs when appropriate, increasing the diversity of the proteins that any single mRNA can produce. The product of the entire transcription process (that began with the production of the pre-mRNA chain) is a mature mRNA chain. |
|
|
|
Translation
Translation (W)
The mature mRNA finds its way to a ribosome, where it gets translated. In prokaryotic cells, which have no nuclear compartment, the processes of transcription and translation may be linked together without clear separation. In eukaryotic cells, the site of transcription (the cell nucleus) is usually separated from the site of translation (the cytoplasm), so the mRNA must be transported out of the nucleus into the cytoplasm, where it can be bound by ribosomes. The ribosome reads the mRNA triplet codons, usually beginning with an AUG (adenine−uracil−guanine), or initiator methionine codon downstream of the ribosome binding site. Complexes of initiation factors and elongation factors bring aminoacylated transfer RNAs (tRNAs) into the ribosome-mRNA complex, matching the codon in the mRNA to the anti-codon on the tRNA. Each tRNA bears the appropriate amino acid residue to add to the polypeptide chain being synthesised. As the amino acids get linked into the growing peptide chain, the chain begins folding into the correct conformation. Translation ends with a stop codon which may be a UAA, UGA, or UAG triplet.
The mRNA does not contain all the information for specifying the nature of the mature protein. The nascent polypeptide chain released from the ribosome commonly requires additional processing before the final product emerges. For one thing, the correct folding process is complex and vitally important. For most proteins it requires other chaperone proteins to control the form of the product. Some proteins then excise internal segments from their own peptide chains, splicing the free ends that border the gap; in such processes the inside "discarded" sections are called inteins. Other proteins must be split into multiple sections without splicing. Some polypeptide chains need to be cross-linked, and others must be attached to cofactors such as haem (heme) before they become functional. |
|
|
|
|
Reverse transcription
Reverse transcription (W)
Reverse transcription is the transfer of information from RNA to DNA (the reverse of normal transcription). This is known to occur in the case of retroviruses, such as HIV, as well as in eukaryotes, in the case of retrotransposons and telomere synthesis. It is the process by which genetic information from RNA gets transcribed into new DNA. |
| |
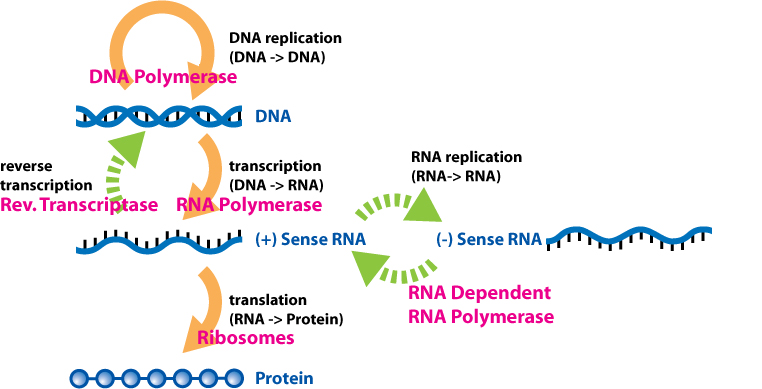
Unusual flows of information highlighted in green. |
|
|
|
|
RNA replication
RNA replication (W)
RNA replication is the copying of one RNA to another. Many viruses replicate this way. The enzymes that copy RNA to new RNA, called RNA-dependent RNA polymerases, are also found in many eukaryotes where they are involved in RNA silencing.
RNA editing, in which an RNA sequence is altered by a complex of proteins and a "guide RNA", could also be seen as an RNA-to-RNA transfer. |
|
|
|
Direct translation from DNA to protein
Direct translation from DNA to protein (W)
Direct translation from DNA to protein has been demonstrated in a cell-free system (i.e. in a test tube), using extracts from E. coli that contained ribosomes, but not intact cells. These cell fragments could synthesize proteins from single-stranded DNA templates isolated from other organisms (e,g., mouse or toad), and neomycin was found to enhance this effect. However, it was unclear whether this mechanism of translation corresponded specifically to the genetic code. |
|
|
|
| |
Transfers of information not explicitly covered in the theory
|
Transfers of information not explicitly covered in the theory
Transfers of information not explicitly covered in the theory (W)
Post-translational modification
After protein amino acid sequences have been translated from nucleic acid chains, they can be edited by appropriate enzymes. Although this is a form of protein affecting protein sequence, not explicitly covered by the central dogma, there are not many clear examples where the associated concepts of the two fields have much to do with each other.
Inteins
An intein is a "parasitic" segment of a protein that is able to excise itself from the chain of amino acids as they emerge from the ribosome and rejoin the remaining portions with a peptide bond in such a manner that the main protein "backbone" does not fall apart. This is a case of a protein changing its own primary sequence from the sequence originally encoded by the DNA of a gene. Additionally, most inteins contain a homing endonuclease or HEG domain which is capable of finding a copy of the parent gene that does not include the intein nucleotide sequence. On contact with the intein-free copy, the HEG domain initiates the DNA double-stranded break repair mechanism. This process causes the intein sequence to be copied from the original source gene to the intein-free gene. This is an example of protein directly editing DNA sequence, as well as increasing the sequence's heritable propagation.
Methylation
Variation in methylation states of DNA can alter gene expression levels significantly. Methylation variation usually occurs through the action of DNA methylases. When the change is heritable, it is considered epigenetic. When the change in information status is not heritable, it would be a somatic epitype. The effective information content has been changed by means of the actions of a protein or proteins on DNA, but the primary DNA sequence is not altered.
Prions
Prions are proteins of particular amino acid sequences in particular conformations. They propagate themselves in host cells by making conformational changes in other molecules of protein with the same amino acid sequence, but with a different conformation that is functionally important or detrimental to the organism. Once the protein has been transconformed to the prion folding it changes function. In turn it can convey information into new cells and reconfigure more functional molecules of that sequence into the alternate prion form. In some types of prion in fungi this change is continuous and direct; the information flow is Protein → Protein.
Some scientists such as Alain E. Bussard and Eugene Koonin have argued that prion-mediated inheritance violates the central dogma of molecular biology. However, Rosalind Ridley in Molecular Pathology of the Prions (2001) has written that "The prion hypothesis is not heretical to the central dogma of molecular biology—that the information necessary to manufacture proteins is encoded in the nucleotide sequence of nucleic acid—because it does not claim that proteins replicate. Rather, it claims that there is a source of information within protein molecules that contributes to their biological function, and that this information can be passed on to other molecules."
Natural genetic engineering
James A. Shapiro argues that a superset of these examples should be classified as natural genetic engineering and are sufficient to falsify the central dogma. While Shapiro has received a respectful hearing for his view, his critics have not been convinced that his reading of the central dogma is in line with what Crick intended. |
|
|
|
|
| |
Use of the term “dogma”
|
Use of the term "dogma"
Use of the term “dogma” (W)
In his autobiography, What Mad Pursuit, Crick wrote about his choice of the word dogma and some of the problems it caused him:
"I called this idea the central dogma, for two reasons, I suspect. I had already used the obvious word hypothesis in the sequence hypothesis, and in addition I wanted to suggest that this new assumption was more central and more powerful. ... As it turned out, the use of the word dogma caused almost more trouble than it was worth. Many years later Jacques Monod pointed out to me that I did not appear to understand the correct use of the word dogma, which is a belief that cannot be doubted. I did apprehend this in a vague sort of way but since I thought that all religious beliefs were without foundation, I used the word the way I myself thought about it, not as most of the world does, and simply applied it to a grand hypothesis that, however plausible, had little direct experimental support."
Similarly, Horace Freeland Judson records in The Eighth Day of Creation:
"My mind was, that a dogma was an idea for which there was no reasonable evidence. You see?!" And Crick gave a roar of delight. "I just didn't know what dogma meant. And I could just as well have called it the 'Central Hypothesis,' or — you know. Which is what I meant to say. Dogma was just a catch phrase."
|
|
|
|
|
| |
Comparison with the Weismann barrier
|
Comparison with the Weismann barrier
Comparison with the Weismann barrier (W)
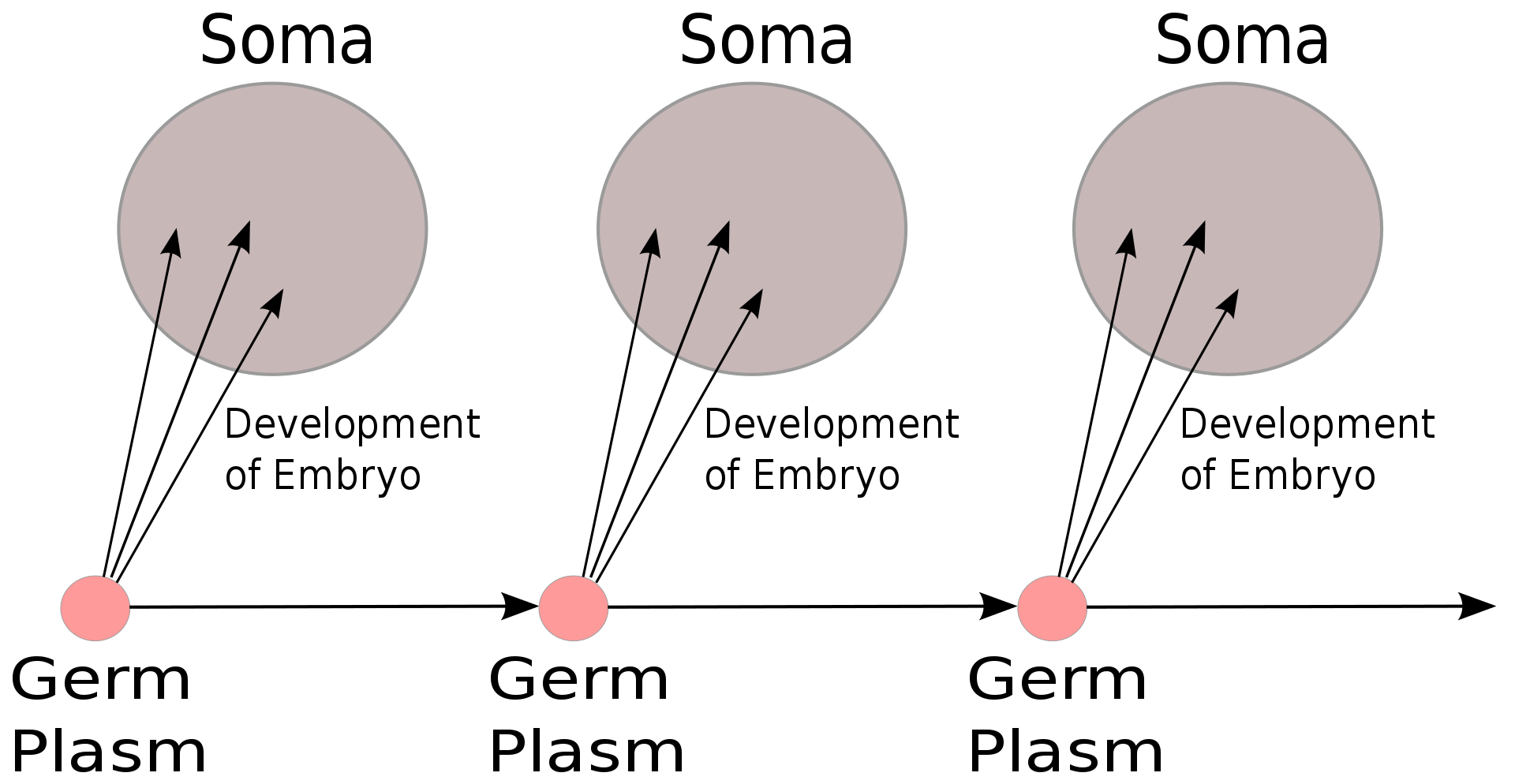
In August Weismann's germ plasm theory, the hereditary material, the germ plasm, is confined to the gonads.) Somatic cells (of the body) develop afresh in each generation from the germ plasm. Whatever may happen to those cells does not affect the next generation.
The Weismann barrier, proposed by August Weismann in 1892, distinguishes between the "immortal" germ cell lineages (the germ plasm) which produce gametes and the "disposable" somatic cells. Hereditary information moves only from germline cells to somatic cells (that is, somatic mutations are not inherited). This, before the discovery of the role or structure of DNA, does not predict the central dogma, but does anticipate its gene-centric view of life, albeit in non-molecular terms. |
| |
In August Weismann's germ plasm theory, the hereditary material, the germ plasm, is confined to the gonads. Somatic cells (of the body) develop afresh in each generation from the germ plasm. Whatever may happen to those cells does not affect the next generation. |
|
|
|
|
|
|
|
|
|
|
|
| |
| |



{kind=link}
{kind=link}
{kind=link}